

{kind=link}
The “AI paradox” is a rising hurdle for enterprise leaders: investing hundreds of thousands in highly effective GPUs, solely to look at them sit idle whereas ready for knowledge. As enterprises scale from pilot to manufacturing, the true bottleneck isn’t compute—it’s the hidden price of an inefficient community. In scale-out architectures, the tens of 1000’s of GPUs should synchronize to finish a single coaching iteration. When the community can’t hold tempo with the bursty calls for of contemporary AI coaching, GPUs stall and job completion time (JCT) spikes. We’ve partnered with AMD to ship a validated, end-to-end AI infrastructure that eliminates these bottlenecks and transforms the community right into a high-performance engine for innovation.
Cloth as the inspiration: The Cisco and AMD AI efficiency blueprint
As AI workloads broaden throughout distributed clusters, the community should scale linearly to forestall packet loss and retransmissions. This efficiency is barely verifiable by rigorous, real-world benchmarking. At Cisco, we prioritize systemic, deterministic efficiency that goes past particular person element specs.
Our reference structure options AMD Intuition™ MI300X GPUs, AMD Pensando™ Pollara 400 NICs, Cisco Silicon One G200-powered N9364E-SG2 switches, and Cisco 800G OSFP optics. Deploying is barely half the problem; working at scale is the opposite. Cisco Nexus Dashboard supplies the granular, real-time visibility wanted for day-0 by day-N operations.

By combining these applied sciences, we reduce JCT and maximize GPU utilization, making certain AI infrastructure stays safe, compliant, and repeatedly optimized.
Benchmarking the structure
We benchmarked two Clos topologies (2×2 & 4×2) with Cisco N9364E-SG2 switches (every with 51.2 Tbps throughput and 64 ports of 800 GbE), 128 AMD Intuition™ MI300X Collection GPUs (16 servers x 8 GPUs), 128 AMD Pensando™ Pollara 400 AI NICs (16 servers x 8 NICs), and the AMD ROCm™ 6.3/7.0.3 software program ecosystem.
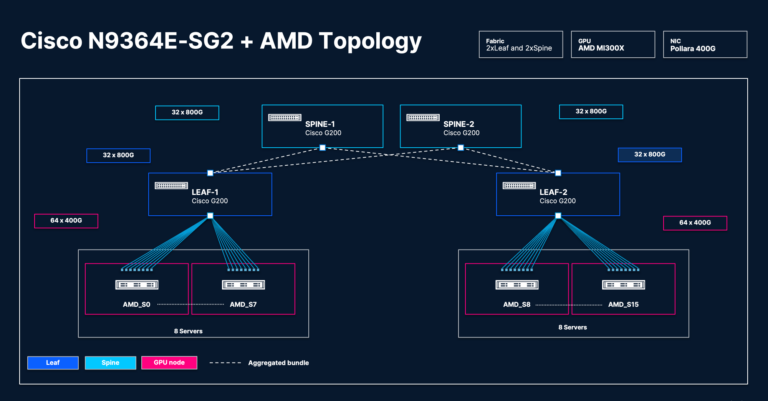
2×2 Clos topology
This design absolutely subscribes every leaf change, forcing the change into high-congestion states to check material resilience:
- 2x leaf and 2x backbone (4x Cisco N9364E-SG2) switches
- 8 servers (8x AMD Intuition™ MI300X Collection GPUs) linked to every leaf change
- 8x AMD Pensando™ Pollara 400G NICs per server
- Change aspect: Cisco OSFP 800G DR8 optics
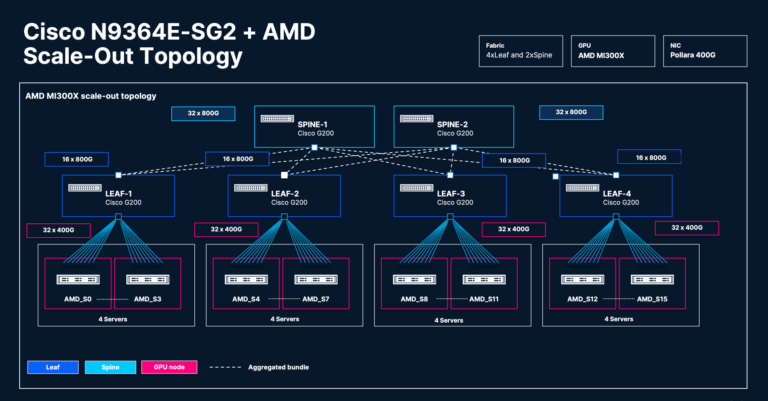
4×2 Clos topology
This design focuses on the efficacy of superior load-balancing strategies for environment friendly load distribution throughout synchronous bursts within the GPU scale-out material:
- 4x leaf and 2x backbone (6x Cisco N9364E-SG2) switches
- 4 servers (8x AMD Intuition™ MI300X Collection GPUs) linked to every leaf change
- 8x AMD Pensando™ Pollara 400G NICs per server
- Change aspect: Cisco OSFP 800G DR8 optics
Benchmarking instruments
We measured scale-out material efficiency utilizing a complete toolset, together with:
- IBPerf measures RDMA efficiency over scale-out material in various congestive eventualities. We used this instrument to check efficiency between GPUs linked throughout a single leaf and throughout leaf-spine.
- MLPerf is an industry-standard benchmark used to measure precise workload efficiency. The efficiency output interprets to ROI on absolutely validated designs from Cisco and AMD.
Community material efficiency benchmarking outcomes
We evaluated scale-out material efficiency utilizing complete testing and commonplace KPIs.
Single-hop IBPerf testing evaluates efficiency inside a localized material area, usually inside a single leaf change. This establishes a baseline for hyperlink utilization, buffer tuning effectiveness, and NIC-to-switch efficiency previous to introducing multi-hop variables.
These exams measure the Distant Direct Reminiscence Entry (RDMA) periods’ throughput between two GPUs linked by a Cisco N9364E-SG2 leaf change. The outcomes seize P01 (1st percentile) and P99 (99th percentile) bandwidth, whereas all of the periods are energetic concurrently. P01 bandwidth represents the throughput of the slowest session—a essential metric for synchronized AI/ML workload efficiency—whereas P99 represents the throughput of the quickest session. A minimal delta between P01 and P99 bandwidth and every bandwidth nearer to the hyperlink bandwidth proves the efficacy of the GPU interconnect expertise.
Within the 2-leaf/2-spine (2×2) topology, every leaf change handles 32 bi-directional periods, successfully saturating the leaf change. The 4-leaf/2-spine (4×2) topology handles 16 bi-directional periods per leaf. Throughout each topologies and ranging queue pair (QP) counts (4 QPs and 32 QPs), the P01 and P99 bandwidths in each topologies and each units of queue pairs are nearer to one another, with every one approaching the hyperlink bandwidth of 400 Gbps.
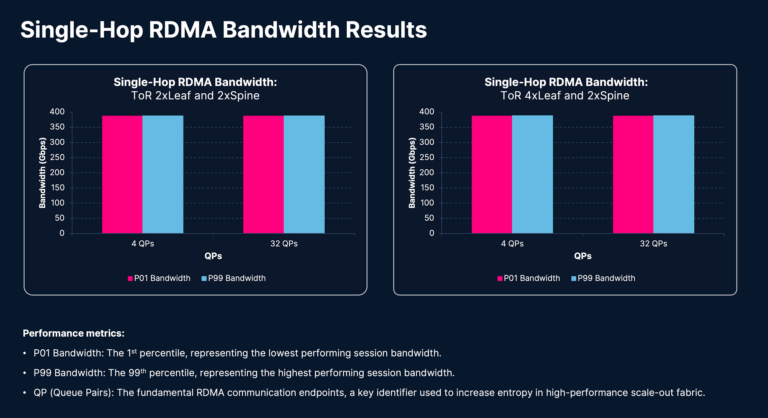
This efficiency reveals that the AMD Pensando™ Pollara NIC and Cisco N9364E-SG2 switches ship a extremely environment friendly resolution for demanding workloads. The tight delta between P01 and P99 metrics throughout completely different scale and configurations demonstrates that this structure maintains deterministic efficiency, no matter cluster dimension or queue pair density.
Bisectional IBPerf testing evaluates cross-fabric visitors traversing a number of tiers to measure bisection bandwidth, path symmetry, cross-spine load balancing, and congestion propagation.
These exams measure RDMA session throughput between two GPUs linked by leaf and backbone Cisco N9364E-SG2 switches. The outcomes present P01 and P99 bandwidth measurements with all periods are concurrently energetic. Within the 2×2 topology, there are 32 bi-directional periods per leaf, whereas the 4×2 topology has 16 bi-directional periods per leaf. All these periods go over backbone. The visitors from every session traverses three hops (leaf-spine-leaf) to emphasize your complete material. This check validates the effectivity of the material’s load-balancing algorithm; any visitors polarization would result in some hyperlinks being underutilized, whereas different hyperlinks turn into congested, finally degrading RDMA session efficiency. Assessments have been carried out utilizing 4 and 32 QPs.
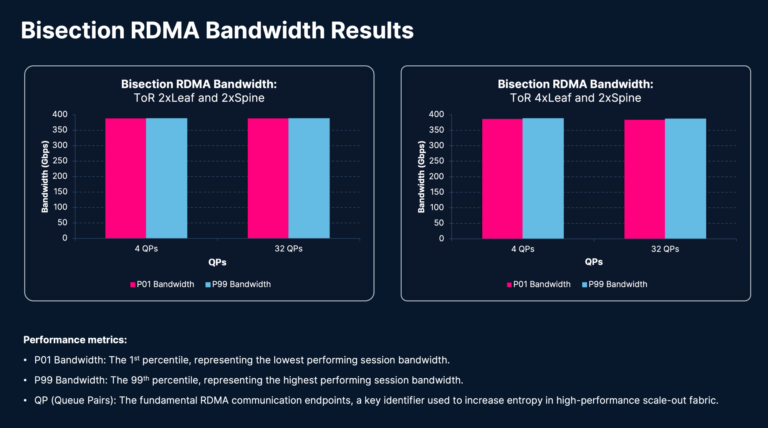
The outcomes reveal that P01 and P99 bandwidths are related and every is nearer to the hyperlink bandwidth of 400 Gbps, mirroring the efficiency noticed in single-hop testing. This confirms that the Cisco N9364E-SG2 switches and AMD Pensando™ Pollara NIC present a high-performance, resilient GPU interconnect expertise able to sustaining constantly deterministic efficiency beneath stress.
Congestive IBPerf testing creates high-contention eventualities utilizing a 31:1 communication sample, the place 31 GPUs talk with a single GPU. It evaluates queue buildup, Specific Congestion Notification (ECN) effectiveness, Knowledge Heart Quantized Congestion Notification (DCQCN) response curves, tail latency, and material stability beneath worst-case AI communication patterns.
Incast circumstances characterize a few of the most difficult eventualities for scale-out AI material. These exams measure P01 and P99 bandwidths beneath incast circumstances, which manifest throughout collective communications comparable to all-to-all. If the scale-out material {hardware}, design, and tuning are usually not optimum, it results in substantial degradation in JCT for coaching workloads. As a result of it’s troublesome to synchronize all periods to begin concurrently, we use the Quantile Vary Methodology to investigate the outcomes. It analyzes bandwidth samples on account of incast congestion as a substitute of all bandwidth samples.
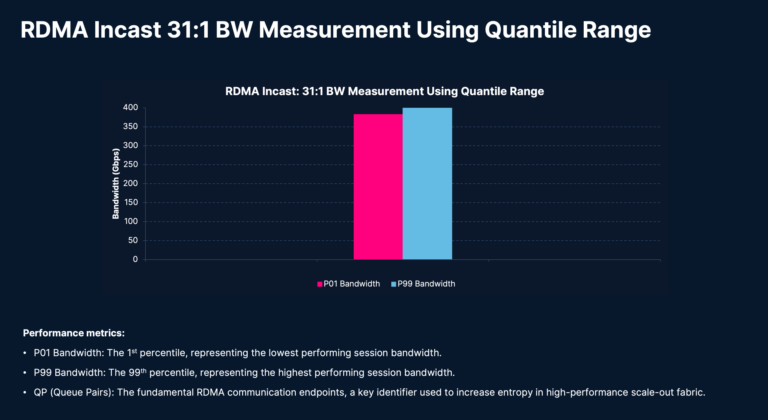
On this check, every of the 128 GPUs establishes 31 RDMA periods to 31 different GPUs throughout the leaf-spine material, leading to a complete of three,968 (31*128 = 3,968) concurrently energetic periods within the scale-out material. The delta between P01 and P99 bandwidth may be very tight, and every bandwidth is near the hyperlink bandwidth of 400 Gbps, which is a stable proof level of the Cisco N9364E-SG2 switches’ potential to deal with excessive congestive circumstances and a testomony to the Cisco and AMD validated design.
MLPerf Coaching and Inference Benchmarking exams set up standardized metrics to judge the efficiency of coaching and inference workloads. By implementing strict pointers relating to fashions, datasets, and allowable optimizations, these benchmarks present a degree enjoying area for truthful comparability amongst competing AI infrastructure options.
The MLPerf exams from MLCommons are designed to supply a standard benchmarking methodology for measuring application-level KPIs, that are the first indicators of efficiency for finish customers. For inference, the Llama 2 70B outcomes reveal clear throughput scaling because the configuration expands from two to 4 nodes. The coaching benchmarks present consultant knowledge for Llama 2 70B (on two nodes) and Llama 3.1 8B (on eight nodes).

These findings present the inspiration for our core declare: the Cisco validated structure is not only theoretically sound; benchmarking reveals it may possibly deal with probably the most demanding AI inference and coaching workloads.
An actual-world deployment of the Cisco and AMD AI resolution structure
The Cisco-AMD partnership delivers real-world impression, notably powering G42’s large-scale AI clusters. This end-to-end resolution—integrating AMD GPUs, Cisco UCS servers, N9000 800G switches, and Nexus Dashboard—supplies the safe, scalable efficiency required for cutting-edge AI workloads.
“As AI workloads scale, community efficiency turns into a essential enabler of cluster effectivity. The AMD Pensando™ Pollara 400 AI NIC, with its absolutely programmable, fault-resilient design, delivers constant efficiency for GPU scale-out coaching. In collaboration with Cisco N9000 switching, we’re advancing Ethernet to the following degree, serving to maximize GPU utilization and speed up job completion.”
—Yousuf Khan, Company Vice President, Networking Expertise and Options Group, AMD
Operationalizing intelligence: A brand new commonplace for efficiency at scale
Within the age of massive-scale AI, a corporation’s infrastructure is both its biggest aggressive benefit or its most important bottleneck. When the stakes contain mission-critical coaching, fine-tuning, and inferencing, a unified, absolutely validated ecosystem is a should. Cisco and AMD are altering the equation, delivering a deterministic, high-performance material that turns your community right into a catalyst for innovation.
Join with a Cisco AI networking specialist in the present day to design a deployment tailor-made to your particular workloads.
Extra assets: