

{kind=link}
As synthetic intelligence (AI) transforms industries globally, the demand for sturdy, scalable, and high-performance infrastructure has reached an all-time excessive. At NVIDIA GTC, we lately unveiled the subsequent era of Cisco Nexus Hyperfabric choices that assist AI, that are purpose-built to speed up innovation and meet the rigorous necessities of recent AI workloads.
What’s Cisco Nexus Hyperfabric?
Cisco Nexus Hyperfabric is a cloud-managed controller designed to simplify how organizations construct and function at the moment’s information facilities and AI environments. Use it as a full-stack platform for speedy deployment or a versatile bring-your-own strategy that permits you to tailor compute, GPUs, software program, and storage to your wants.
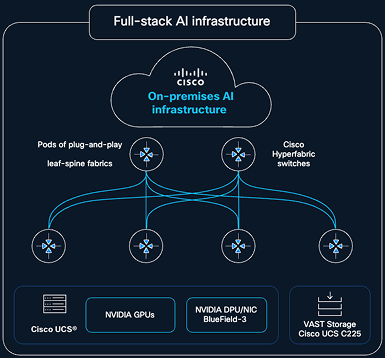
The complete-stack AI infrastructure possibility brings collectively cloud-managed networking, compute with NVIDIA GPUs, elective storage with VAST Knowledge, and automation right into a validated structure that’s NVIDIA Enterprise Reference Structure (ERA) compliant, eradicating the complexity of integrating and managing infrastructure throughout a number of layers. As proven in Determine 1, a centralized cloud management airplane streamlines design, deployment, and operations, enabling enterprises and neocloud suppliers to scale AI workloads quicker and transfer confidently from experimentation to manufacturing.
Networking breakthrough: Cisco N9164E with NVIDIA Spectrum-4 with Nexus Hyperfabric
AI workloads are solely as efficient because the networks connecting compute nodes. Huge parallel processing in AI clusters requires ultra-low latency, excessive bandwidth, and lossless information switch. Enter the Cisco N9164E-NS4-O change, an 800G powerhouse that integrates NVIDIA Spectrum-4 ASICs for state-of-the-art efficiency.
We’ve built-in the NVIDIA Spectrum-4–based mostly Cisco Nexus 9164E into Cisco Nexus Hyperfabric, additional enhancing high-performance AI networking. This addition strengthens the flexibility of Nexus Hyperfabric to ship scalable, low-latency connectivity for large-scale AI workloads whereas supporting NCP-compliant AI infrastructure deployments.
Highlights of the N9164E change embody the next:
- 800G ports: Delivering as much as 64 ports of 800G Ethernet in a compact, energy-efficient type issue.
- NVIDIA Spectrum-4 inside: Superior ASICs designed particularly for AI workloads, enabling Distant Direct Reminiscence Entry over Converged Ethernet model 2 (RoCEv2) and enhanced congestion management.
- Deterministic, predictable efficiency: Important for distributed AI coaching, making certain GPUs throughout the cluster can talk at peak effectivity.
- Telemetric insights and automation: Deep visibility and programmability for community operators, simplifying troubleshooting and optimizing useful resource allocation. This differs from some conventional information middle switches, providing the uncooked community throughput and intelligence wanted for the most recent AI supercomputing clusters.
Ushering within the subsequent wave of AI infrastructure with Nexus Hyperfabric
To scale AI with confidence, organizations want highly effective compute, validated architectures, and deep ecosystem integration. Cisco Nexus Hyperfabric brings these components collectively by means of GPU-accelerated compute, NVIDIA Cloud Accomplice (NCP)–compliant designs, and a tightly built-in Cisco–NVIDIA stack constructed for AI at scale.
Compute powerhouse: Cisco UCS 880 with NVIDIA HGX B300 NVL8 GPUs
On the coronary heart of any AI infrastructure lies compute—highly effective servers designed to effectively course of large datasets and sophisticated algorithms. With its new availability with Cisco Nexus Hyperfabric, the Cisco UCS 880 system paired with B300 blades will ship purpose-built compute designed for demanding AI coaching and inference workloads, supporting the most recent NVIDIA GPUs and high-bandwidth interconnects.
Key options of the Cisco UCS 880 rack server with NVIDIA HGX B300 NVL8 GPUs embody:
- Excessive-density, modular design: Scalable to fulfill rising workload calls for with out compromising on power effectivity or footprint.
- Optimized GPU assist: Future-proofed for the most recent GPU architectures, making certain that clients can leverage one of the best of AI acceleration.
- Seamless integration: Constructed to suit into current Cisco UCS environments, simplifying deployment and administration for enterprise IT groups.
Why NVIDIA Cloud Accomplice compliance issues
One of many standout elements of the brand new Cisco Nexus Hyperfabric options is that they adjust to the NCP program. However what precisely is NCP, and why is it a game-changer for organizations constructing AI infrastructure?
What’s NVIDIA Cloud Accomplice compliance
NCP is a rigorous certification and best-practices program established by NVIDIA to make sure that cloud and information middle infrastructure companions ship the very best ranges of efficiency at scale, reliability, and compatibility for AI workloads. NCP-compliant options are validated to work seamlessly with the NVIDIA AI stack, together with GPUs, networking, and software program frameworks akin to NVIDIA CUDA, the CUDA Deep Neural Community library (cuDNN), and NVIDIA AI Enterprise.
NCP is necessary for AI Infrastructure to assist present:
- Assured compatibility: Clients can deploy Cisco Nexus Hyperfabric options with confidence, understanding they’ll work out of the field with NVIDIA GPUs and software program stacks.
- Efficiency optimization: NCP compliance ensures tuning and optimizations that maximize throughput, decrease latency, and remove bottlenecks—important for distributed AI coaching jobs.
- Enterprise assist and upgrades: Companies profit from a streamlined assist expertise, with each Cisco and NVIDIA backing the answer, plus entry to the most recent options and enhancements.
- Sooner time to worth: Organizations can concentrate on AI innovation fairly than infrastructure integration and troubleshooting.
NCP compliance positions Cisco Nexus Hyperfabric options as a trusted basis for personal, hybrid, and partner-hosted AI clouds, accelerating innovation whereas decreasing deployment danger.
The Cisco–NVIDIA benefit: Remodeling AI at scale
The synergy between Cisco and NVIDIA is foundational to those new options. Cisco brings a long time of management in networking and information middle structure, whereas NVIDIA supplies the acceleration applied sciences powering the world’s most formidable AI initiatives. This mix addresses the important challenges that organizations face as they scale up their AI initiatives, together with:
- Knowledge explosion: With extra information than ever being generated, high-performance networking from Cisco ensures that information flows effectively to the place it’s wanted.
- AI mannequin complexity: As AI fashions develop in each dimension and class, solely tightly built-in compute and community options—like Cisco UCS 880/B300 and Nexus 9164E—can sustain.
- Operational intricacy: NCP compliance and automation options cut back complexity, so IT groups can concentrate on delivering outcomes, not managing infrastructure trivialities.
Your path to AI at scale
Our bulletins at NVIDIA GTC mark a pivotal second for AI infrastructure. Cisco Nexus Hyperfabric options—anchored by the Cisco UCS 880 with B300 blades and Nexus 9164E (800G) switches with NVIDIA Spectrum-4—are purpose-built for the period of AI at scale. With NVIDIA Cloud Accomplice compliance, these options set a brand new normal for efficiency, compatibility, and ease of deployment.
As you scale AI, you’ll want infrastructure that’s confirmed, versatile, and prepared for manufacturing. Cisco Nexus Hyperfabric delivers a validated basis for contemporary AI environments by uniting highperformance networking, GPUaccelerated compute, and NCPaligned architectures. The result’s a platform that simplifies deployment and operations whereas supporting AI workloads from growth by means of full-scale manufacturing.
AI with Nexus Hyperfabric allows two validated paths to production-grade AI infrastructure. For enterprises, Nexus Hyperfabric aligns with NVIDIA ERA compliance to ship a safe AI manufacturing facility with a full-stack, cloud-managed platform that integrates compute, NVIDIA GPUs, networking, storage, and software program with deterministic efficiency and operational simplicity. For neocloud suppliers, Nexus Hyperfabric helps NCP-compliant architectures, enabling scalable GPU-as-a-service choices that speed up tenant onboarding, simplify lifecycle operations, and ship predictable efficiency for multi-tenant AI workloads. Collectively, these paths present a basis for constructing and scaling AI infrastructure with confidence.
With Nexus Hyperfabric and the Cisco–NVIDIA ecosystem, you possibly can construct and scale AI with confidence. Discover Nexus Hyperfabric hands-on before you purchase, at hyperfabric.cisco.com. Or get extra data concerning the resolution earlier than you attempt.