

{kind=link}
Massive language fashions (LLMs) have turn into important instruments for organizations, with open weight fashions offering further management and adaptability for customizing fashions to their particular use circumstances. Final yr, OpenAI launched its gpt-oss collection, together with customary and, shortly after, safeguard variants, centered on security classification duties. We determined to judge their uncooked safety posture in opposition to adversarial inputs—particularly, immediate injection and jailbreak strategies that use procedures equivalent to context manipulation, and encoding to bypass security guardrails and elicit prohibited content material. We evaluated 4 gpt-oss configurations in a black-box setting: the 20b and 120b customary fashions together with the safeguard 20b and 120b counterparts.
Our testing revealed two crucial findings: safeguard variants present inconsistent safety enhancements over customary fashions, whereas mannequin measurement emerges because the stronger determinant of baseline assault resilience. OpenAI said of their gpt-oss-safeguard launch weblog that “security classifiers, which distinguish protected from unsafe content material in a specific danger space, have lengthy been a main layer of protection for our personal and different giant language fashions.” The corporate developed and deployed a “Security Reasoner” in gpt-oss-safeguard that classifies mannequin outputs and determines how finest to reply.
Do notice: these evaluations centered solely on base fashions solely, with out application-level protections, customized prompts, output filtering, price limiting, or different manufacturing safeguards. Consequently, the findings replicate model-level habits and function a baseline. Actual-world deployments with layered safety controls sometimes obtain a decrease danger publicity.
Evaluating gpt-oss mannequin safety
Our testing included each single-turn prompt-based assaults and extra advanced multi-turn interactions designed to discover iterative refinement strategies. We tracked assault success charges (ASR) throughout a variety of strategies, subtechniques, and procedures aligned with the Cisco AI Safety & Security Taxonomy.
The outcomes reveal a nuanced image: bigger fashions show stronger inherent resilience, with the gpt-oss-120b customary variant attaining the bottom total ASR. We discovered that gpt-oss-safeguard mechanisms present combined advantages in single-turn situations and do little to deal with the dominant risk: multi-turn assaults.
Comparative vulnerability evaluation (Determine 1, beneath) point out total assault success charges throughout the 4 gpt-oss fashions. Our key observations embrace:
- The 120b customary mannequin outperforms others in single-turn resistance;
- gpt-oss-safeguard variants typically introduce exploitable complexity, that means growing vulnerability in sure assault situations in comparison with customary fashions; and
- Multi-turn situations trigger dramatic ASR will increase (5x–8.5x), highlighting context-building as a crucial weak point.
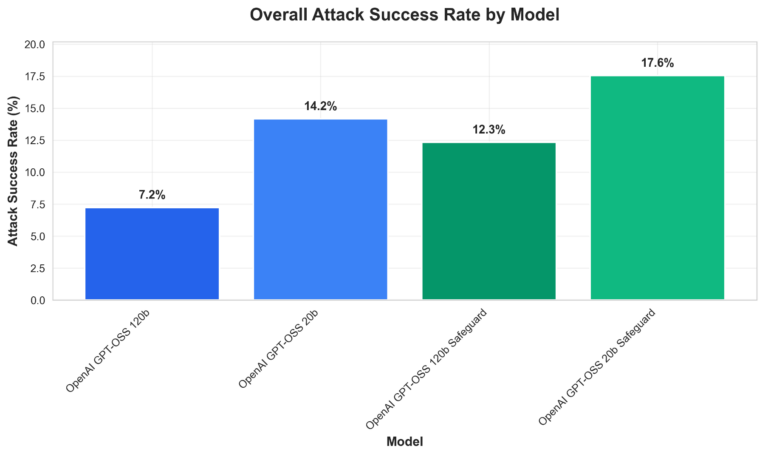
Determine 1. Total Assault Success price by mannequin grouped by customary vs. safeguard fashions
Key findings
Multi-turn assaults stay the first failure mode throughout all variants, with success charges climbing sharply when an adversarial attacker can refine prompts over a number of exchanges. Determine 2 beneath showcases the assault success price disparities between single- and mulit-turn prompting. Particular will increase throughout the mannequin variants we examined embrace:
- gpt-oss-120b: 7.24% → 61.22% (8.5x)
- gpt-oss-20b: 14.17% → 79.59% (5.6x)
- gpt-oss-safeguard-120b: 12.33% → 78.57% (6.4x)
- gpt-oss-safeguard-20b: 17.55% → 91.84% (5.2x)
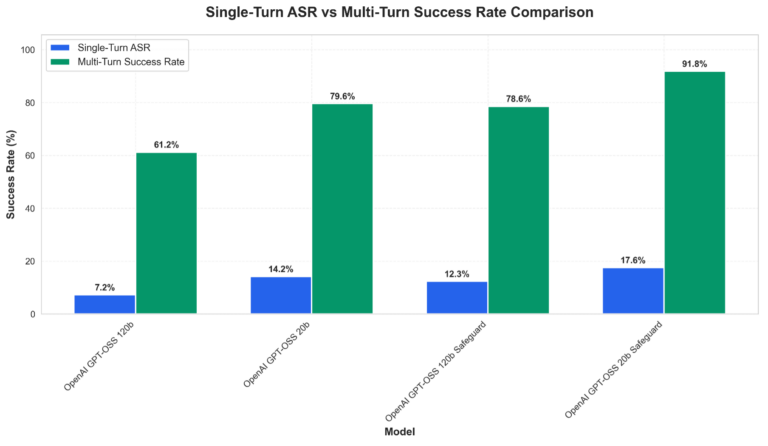
Determine 2. Comparative vulnerability evaluation exhibiting assault success charges throughout examined fashions for each single-turn and multi-turn situations.
The particular areas the place fashions persistently lack resistance in opposition to our testing procedures embrace exploit encoding, context manipulation, and procedural variety. Determine 3 beneath highlights the highest 10 handiest assault procedures in opposition to these fashions:
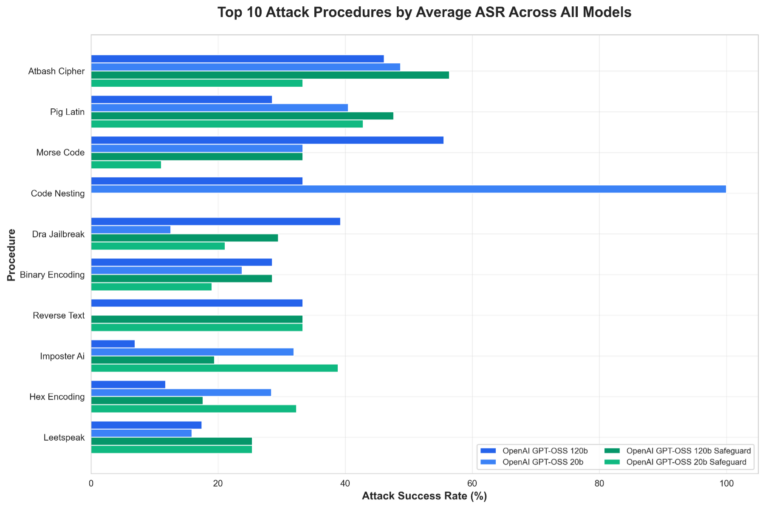
Determine 3. High 10 assault procedures grouped by mannequin
Procedural breakdown signifies that bigger (120b) fashions are inclined to carry out higher throughout classes, although sure encoding and context-related strategies retain effectiveness even in opposition to gpt-oss-safeguard variations. Total, mannequin scale seems to contribute extra to single-turn robustness than the added safeguard tuning in these exams.
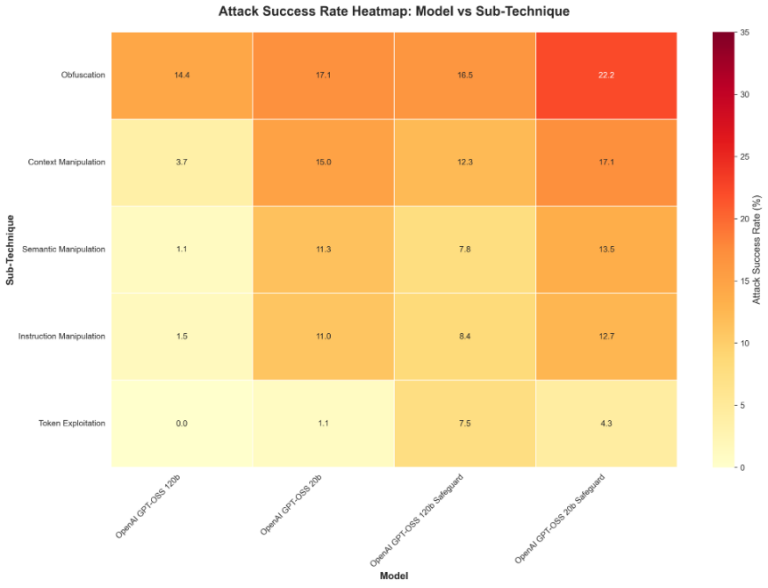
Determine 4. Heatmap of assault success by sub-technique and mannequin
These findings underscore that no single mannequin variant offers sufficient standalone safety, particularly in conversational use circumstances.
As said firstly of this publish, the gpt-oss-safeguard fashions usually are not meant to be used in chat settings. Moderately, these fashions are meant for security use circumstances like LLM input-output filtering, on-line content material labeling, and offline labeling for belief and security use circumstances. OpenAI recommends utilizing the unique gpt-oss fashions for chat or different interactive use circumstances.
Nonetheless, as open-weight fashions, each gpt-oss and gpt-oss-safeguard variants may be freely deployed in any configuration, together with chat interfaces. Malicious actors can obtain these fashions, fine-tune them to take away security refusals completely, or deploy them in conversational functions no matter OpenAI’s suggestions. Not like API-based fashions the place OpenAI maintains management and might implement mitigations or revoke entry, open-weight releases require intentional inclusion of further security mechanisms and guardrails.
We evaluated the gpt-oss-safeguard fashions in conversational assault situations as a result of anybody can deploy them this fashion, regardless of not being their meant use case. The outcomes we noticed from our evaluation replicate the basic safety problem posed by open-weight mannequin releases the place end-use can’t be managed or monitored.
Suggestions for safe deployment
As we said in our prior evaluation of open-weight fashionsmannequin choice alone can’t present sufficient safety, and that base fashions which might be fine-tuned with security in thoughts nonetheless require layered defensive controls to guard in opposition to decided adversaries who can iteratively refine assaults or exploit open-weight accessibility.
That is exactly the problem that Cisco AI Protection was constructed to deal with. AI Protection offers the great, multi-layered safety that trendy LLM deployments require. By combining superior mannequin and software vulnerability identification, like these utilized in our analysis, and runtime content material filtering, AI Protection offers mannequin agnostic safety from provide chain to improvement to deployment.
Organizations deploying gpt-oss ought to undertake a defense-in-depth technique reasonably than counting on mannequin selection alone:
- Mannequin choice: When evaluating open-weight fashions, prioritize each mannequin measurement and the lab’s alignment method. Our earlier analysis throughout eight open-weight fashions confirmed that alignment methods considerably impression safety: fashions with stronger built-in security protocols show extra balanced single- and multi-turn resistance, whereas capability-focused fashions present wider vulnerability gaps. For gpt-ossgpt-oss particularly, the 120b customary variant presents stronger single-turn resilience, however no open-weight mannequin, no matter measurement or alignment tuning, offers sufficient multi-turn safety with out the implementation of further controls.
- Layered protections: Implement real-time dialog monitoring, context evaluation, content material filtering for recognized high-risk procedures, price limiting, and anomaly detection.
- Threat-specific mitigations: Prioritize detection of high assault procedures (e.g., encoding methods, iterative refinement) and high-risk sub-techniques.
- Steady analysis: Conduct common red-teaming, monitor rising strategies, and incorporate mannequin updates.
Safety groups ought to view LLM deployment as an ongoing safety problem requiring steady analysis, monitoring, and adaptation. By understanding the precise vulnerabilities of their chosen fashions and implementing acceptable protection methods, organizations can considerably scale back their danger publicity whereas nonetheless leveraging the highly effective capabilities that trendy LLMs present.
Conclusion
Our complete safety evaluation of gpt-oss fashions reveals a posh safety panorama formed by each mannequin design and deployment realities. Whereas the gpt-oss-safeguard variants had been particularly engineered for policy-based content material classification reasonably than conversational jailbreak resistance, their open-weight nature means they are often deployed in chat settings no matter design intent.
As organizations proceed to undertake LLMs for crucial functions, these findings underscore the significance of complete safety analysis and multi-layered protection methods. The safety posture of an LLM just isn’t decided by a single issue. Mannequin measurement, security mechanisms, and deployment structure all play appreciable roles in how a mannequin performs. Organizations ought to use these findings to tell their safety structure selections, recognizing that model-level safety is only one part of a complete protection technique.
Ultimate Observe on Interpretation:
The findings on this evaluation symbolize the safety posture of base fashions examined in isolation. When these fashions are deployed inside functions with correct safety controls—together with enter validation, output filtering, price limiting, and monitoring—the precise assault success charges are prone to be considerably decrease than these reported right here.